I recently picked up “How Machines Learn” by Anil Ananthswamy (gifted by my gf) and was blown away by how it traces the roots of artificial intelligence back to the earliest models of artificial neurons which were inspired by the very cells firing in your brain right now.
In this post, we’ll build an intuition on how these foundational models were devised, break down the maths behind it in a simple and visual way, and see just how closely they mirror real neurons. Plus, there might be a meme or two to keep things lively. It’s going to be a long read ;)

The Real Deal: Biological Neurons
We all know Neurons are cells found in Nervous system and it’s main job is to transmit electrical and chemical signals throughout the body.
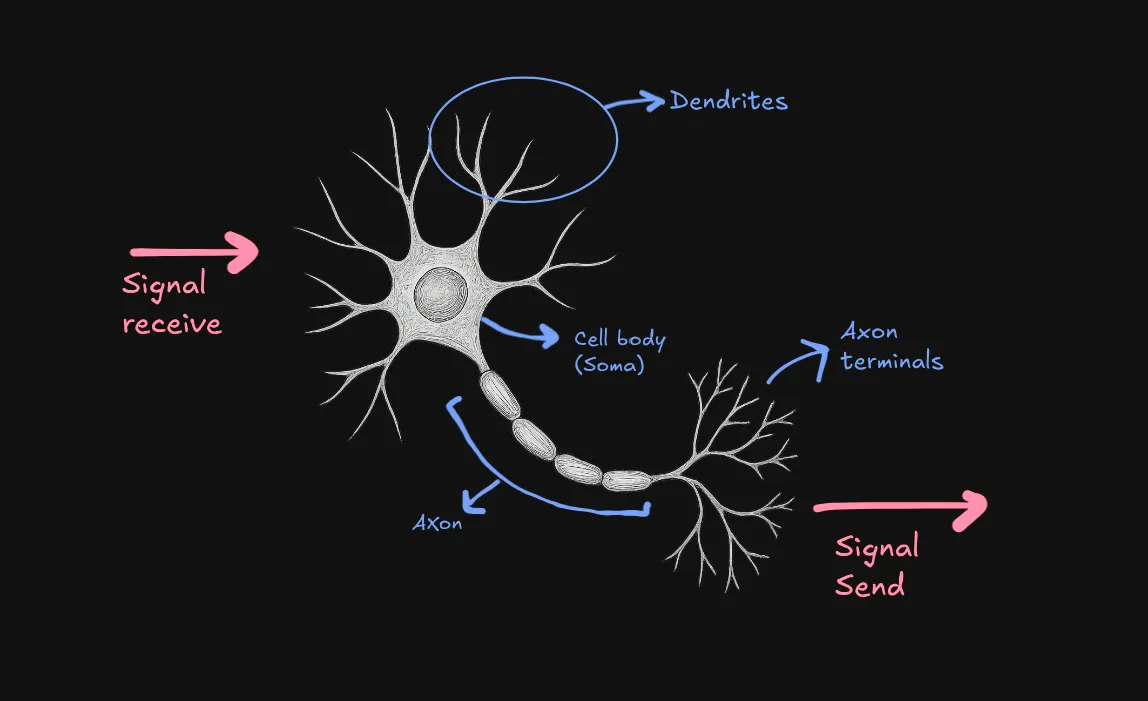
How do neurons work?
-
Dendrites: these are like thousands of tiny antennas, each receive signals from other neurons
-
Signals: these are electrochemical signals and one thing to note is each signal has it’s importance meaning one signal can be less important than other. Signals can be excitatory (encouraging the neuron to fire) or inhibitory (discouraging it)
-
Cell body/Soma: All the incoming signals gather up at the body and it decides whether to fire the signal or not. If the combines importance of the excitatory signal minus the inhibitory signal exceeds this threshold -> Boom the neuron fires.
-
Axon & Terminals: This is like a dedicated output cable, carrying the decision. Axon terminals are like broadcast stations, sending the signal to dendrites of other neurons
Neuron working analogy
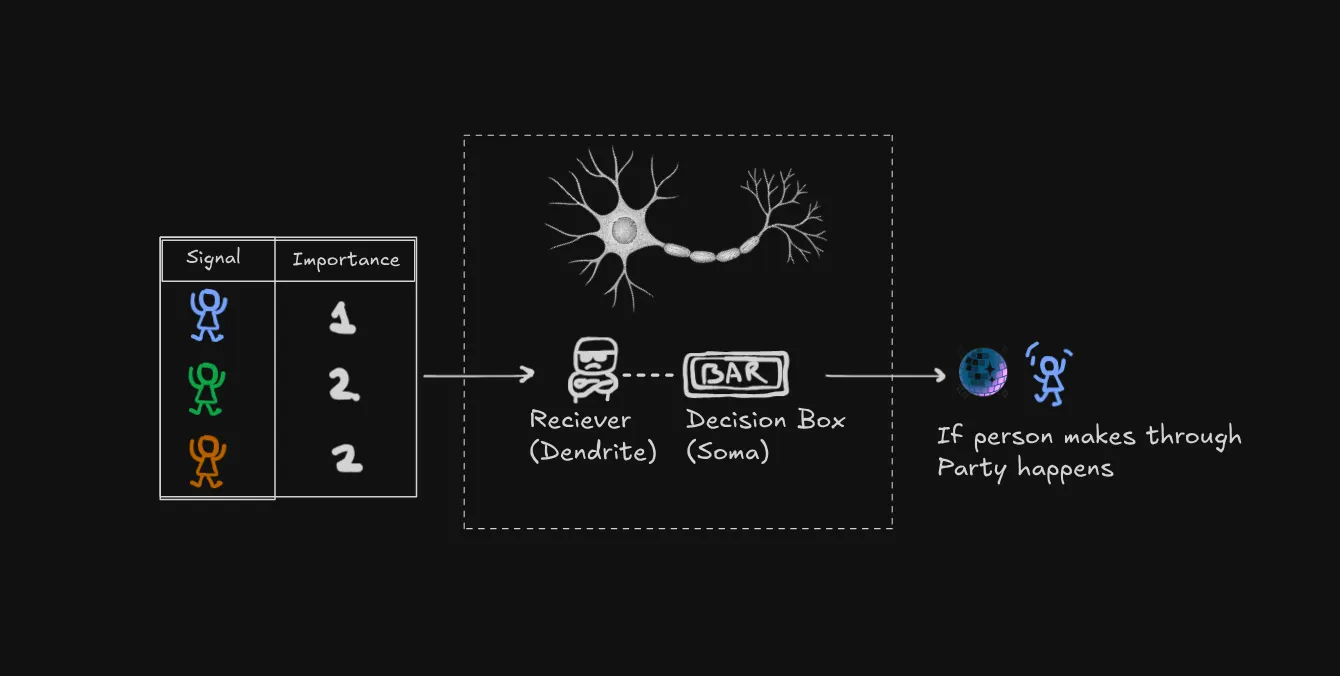
Think of it like a bar with the world’s most mathematical bouncer. Let’s break down how this party (I mean, neuron ;) works:
- Every person (signal) has a specific importance value (weight)
- Normal people count as 1
- VIPs count as 2 (they’re twice as important!)
- Police/party-poopers count as -2 (they actually work against the party starting)
- The party only starts when the total “party value” hits a certain threshold
The Basic Party Math
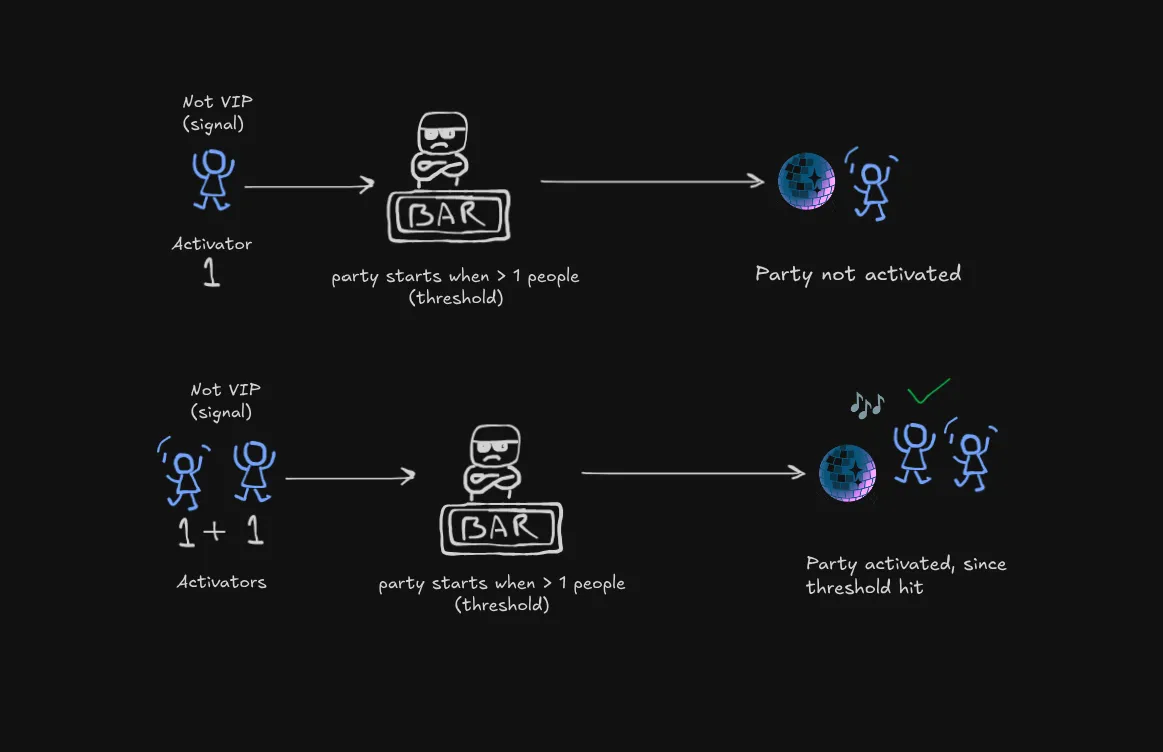
When just one regular person shows up (value = 1), and the threshold is > 1, no party happens. But when two regular people arrive (1 + 1 = 2), boom! We hit the threshold, and the party (neuron) activates!
When Things Get Interesting
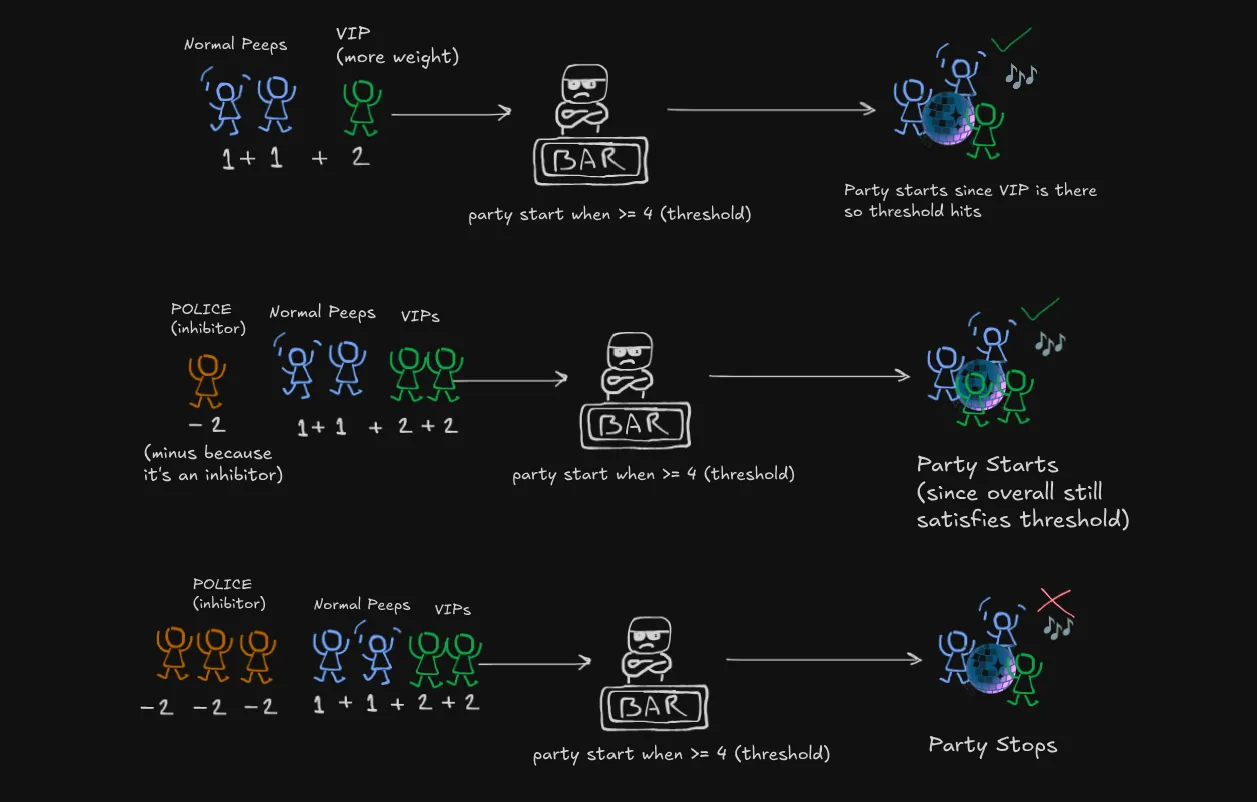
Now this is where our bouncer’s math gets spicy (just like real-world drama):
Scene 1: Two regular college buddies show up , but wait… who’s that rolling up in a Mercedes? Oh snap, it’s the minister’s son and his influential friend ! Total party value hits and Party mode: ACTIVATED! 🎉
Scene 2: A police officer shows up after getting noise complaints. But lucky for us, we’ve got our the minister’s son and his equally influential friend . Even with Officer Party-Pooper, the vibe stays alive because .
Diplomatic immunity for the win! (‘Janta hai mera baap kon hai?’_)
Scene 3: Plot twist! Turns out he was just pretending to be a minister’s son.
Three real police officers . Even with our regular squad and the influential friend , the party gets shut down faster than he can say “My dad will hear about this!” Because
Moral of the story? Just like neurons, it’s all about balance - and maybe don’t lie about being a minister’s kid! 😅
Just like this bouncer, a neuron:
- Adds up excitatory signals (party people)
- Subtracts inhibitory signals (police)
- Only “fires” (starts the party) when the total hits the threshold
- Stays quiet (no party) when it doesn’t

Well that’s what McCulloch Pitts Neuron (MCP) Neuron does. It’s a super simplified binary version of a real neuron.
Threshold for biological neurons
**You must be wondering who set’s biological neuron’s threshold? **
In biological neurons, the “threshold” is called Action Potential and it’s determined by the neuron’s properties and the environment.
The threshold can change based on chemicals in the brain, fatigue, or recent activity (for example, after firing a lot, a neuron might temporarily raise its threshold to avoid overloading).
So, in the brain, the threshold is a dynamic property, influenced by genetics, experience, and the neuron’s current state.
McCulloch Pitts Neuron (MCP)
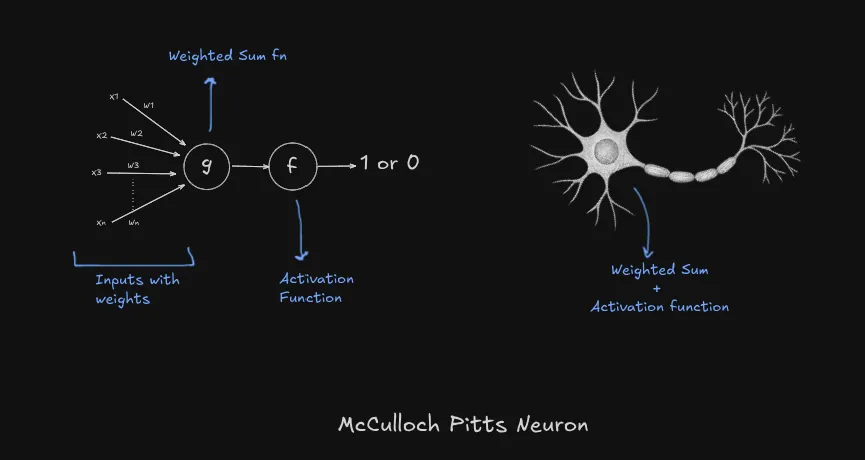
Here is how it works:
- Takes weighted inputs and sums them up
- Passes weighted sum to the activation function
- Activation function based on threshold produces binary output or
Explanation (Why binary output?)
Why binary output?
Because back then due to limited understanding of neurons, scientists were under the assumption that neurons had two state: Fires or Doesn’t fire.
Now we know that Neurons produces spectrum of outputs and there are a lot more elements involved into it and we have more advanced models to mimic that.
Activation function
An activation function is like a decision-maker for a neuron, like the Soma (cell body).
It takes total signal a neuron receives (after adding all of the weighted inputs) and determines what the output should be, which is usually transformed into something useful like 0 or 1, or a number between 0 and 1.
The MCP neuron uses Step Function i.e it returns binary output based on the input meeting the given a threshold criteria.
being the output of the activation function and being input (total signal/weighted sum) or in other terms is the output of the weighted sum function.
Intuition (Intuition)
If you get anxious seeing such mathy fonts, here’s a flow diagram to help build intuition:
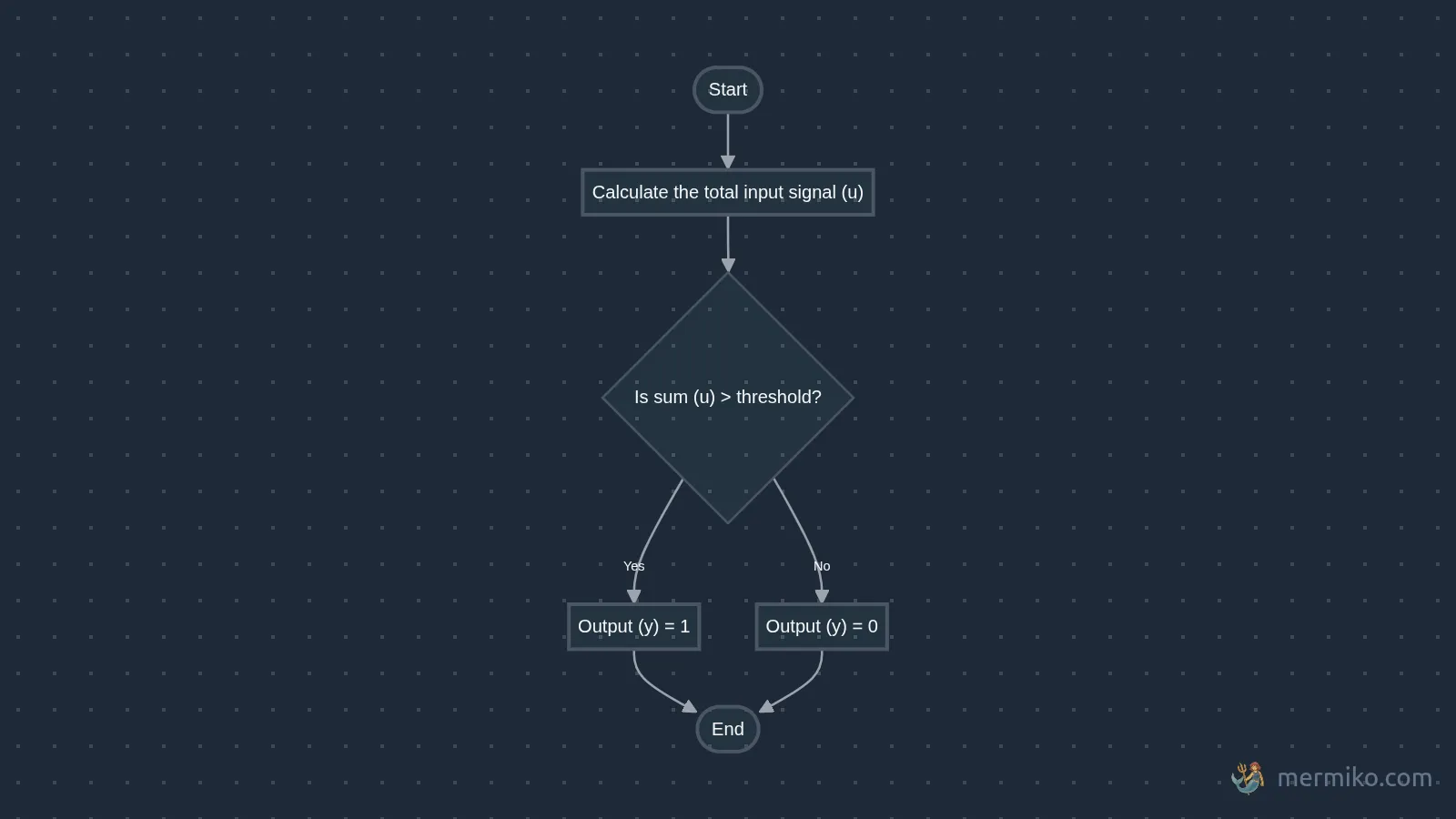
This is also used in perceptron as we’ll discuss further. But the question is what can we do with it?
Implementing MCP Neuron
Let’s implement it in code. We’ll use Python to create a simple implementation of the MCP neuron.
Example (Python Implementation: MCP Neuron)
This class takes a list of weights and a threshold, computes the weighted sum of the inputs, and applies a step activation function:
class MCPNeuron:
def __init__(self, weights, theta):
self.weights = weights
self.theta = theta
def weighted_sum(self, inputs):
return sum(i * w for i, w in zip(inputs, self.weights))
def step_function(self, u):
return int(u >= self.theta) # returns 1 if threshold met, else 0
def activate(self, inputs):
u = self.weighted_sum(inputs)
return self.step_function(u)Implementing Logic Gates using MCP
Why are we suddenly talking about logic gates? Well, it turns out MCP neurons can do something pretty neat: they can simulate basic logical operations. This was one of the first practical applications that got researchers excited.
Just by choosing different weights and thresholds, we can make it perform logical operations. Let’s see how:
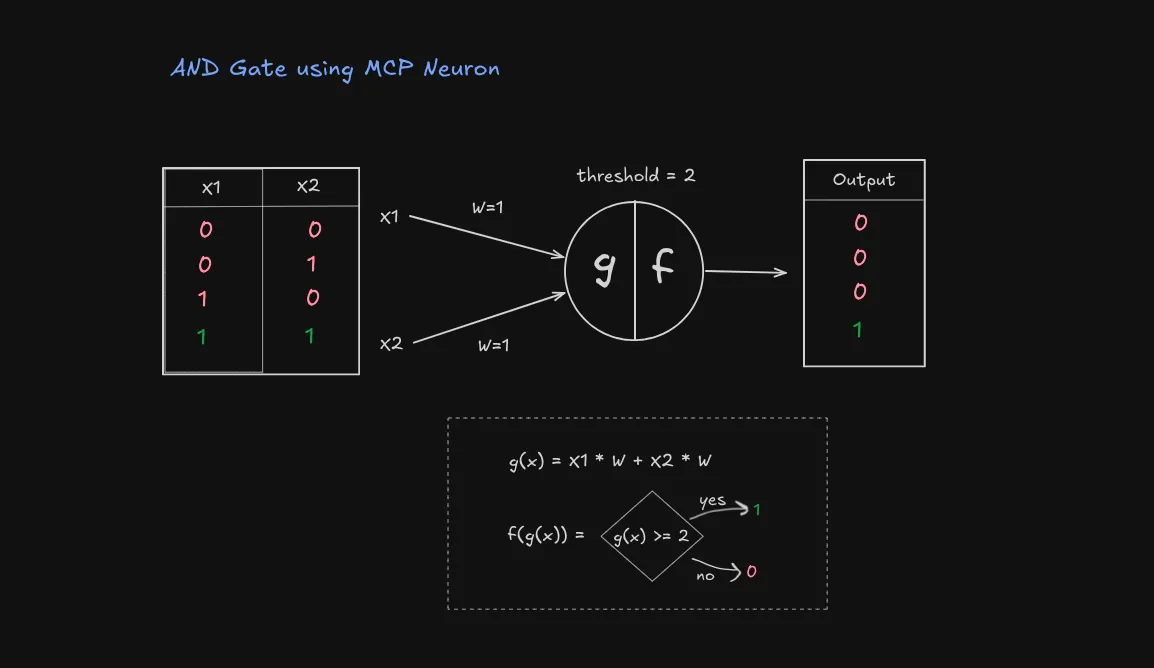
The AND Gate
First, let’s look at the AND operation:
| Input 1 | Input 2 | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
To make an MCP neuron behave like an AND gate:
- Give both inputs a weight of 1
- Set threshold to 2
- This way, we only get output 1 when BOTH inputs are 1 (1 + 1 ≥ 2)
Example (Implementing AND Gate)
Here’s how we can implement the AND gate using our MCP neuron:
weights = [1,1]
threshold = 2
andGate = MCPNeuron(weights,threshold)
inputs = [1,1] # try out other inputs
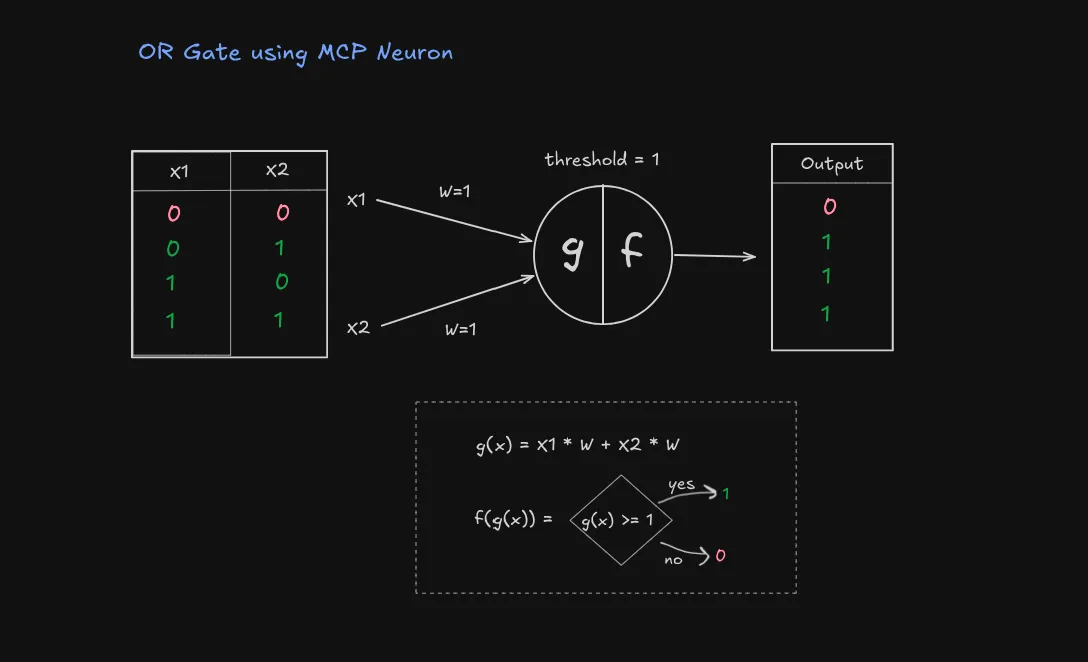
print(andGate.activate(inputs))The OR Gate
The OR operation outputs true if ANY input is true:
| Input 1 | Input 2 | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
To create an OR gate:
- Keep weights at 1 each
- Lower threshold to 1
- Now we get output 1 if ANY input is 1 (because 1 ≥ 1)
Example (Implementing AND Gate)
Here’s how we can implement the OR gate using our MCP neuron:
weights = [1,1]
threshold = 1
orGate = MCPNeuron(weights,threshold)
inputs = [1,1] # try out other inputs
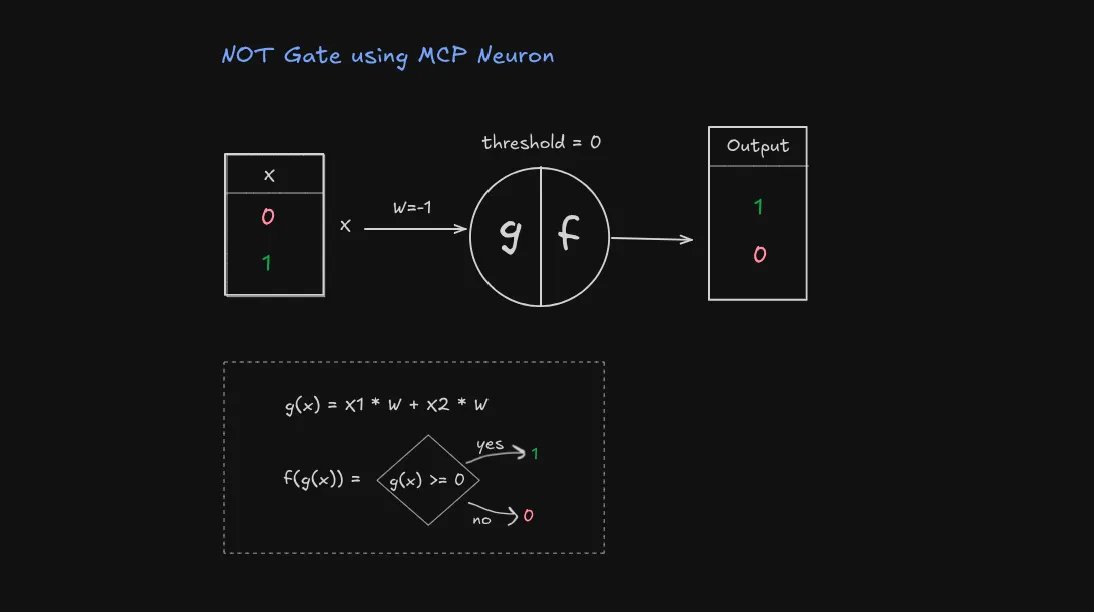
print(orGate.activate(inputs))NOT gate (Inhibitor signal)
The NOT gate is particularly interesting because it mirrors how inhibitory signals work in biological neurons. Remember how our bouncer dealt with party-poopers? This is similar!
| Input | Output |
|---|---|
| 0 | 1 |
| 1 | 0 |
To create a NOT gate using an MCP neuron:
- Give the input a negative weight (-1): 👈 this makes it inhibitory
- Set threshold to 0
- When input is 1: (-1 × 1) = -1 < 0, output 0
- When input is 0: (-1 × 0) = 0 ≥ 0, output 1
Example (Implementing NOT Gate)
Here’s how we can implement the NOT gate using our MCP neuron:
weights = [-1]
threshold = 0
notGate = MCPNeuron(weights,threshold)
inputs = [1] # try out other inputs
print(notGate.activate(inputs))Exercise (Try it yourself!)
- Try designing other logic gates (like NAND, NOR, XOR) using the MCP neuron model.
- Can you find a gate that cannot be implemented with a single MCP neuron? (Hint: XOR)
- Think about why some gates work and others don’t, what’s special about their logic?
- Try chaining multiple MCP neurons to create more complex logic.
Linear Separability
Definition (Linear Separability)
A problem is said to be linearly separable if you can draw a straight line (or hyperplane in higher dimensions) that can separate the data into different classes.
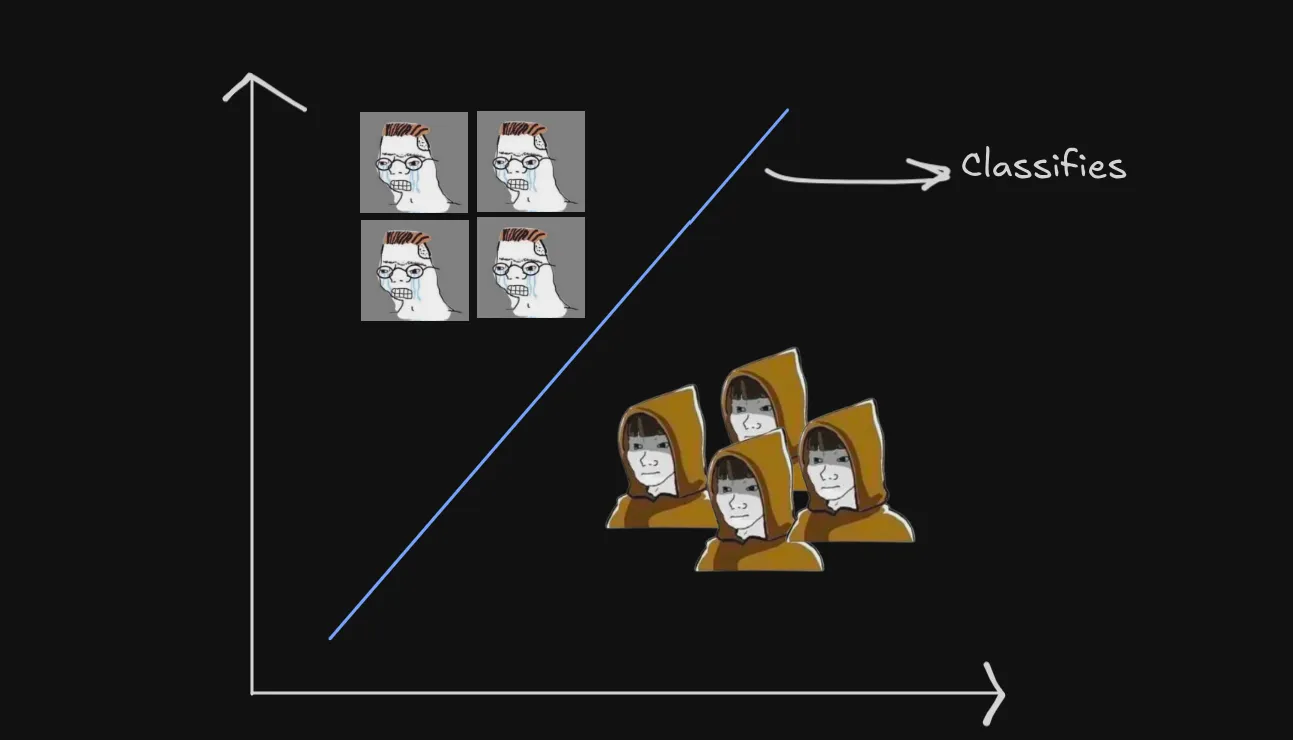
Let’s visualize the whole process on a graph. Suppose we have two inputs: temperature and humidity and we need decide if we go outside (output 1) or stay in (output 0).
To recap, MCP neuron takes these inputs, gives them weights (how important they are), adds them up, and checks against a threshold.
Proof (Translating to graph)
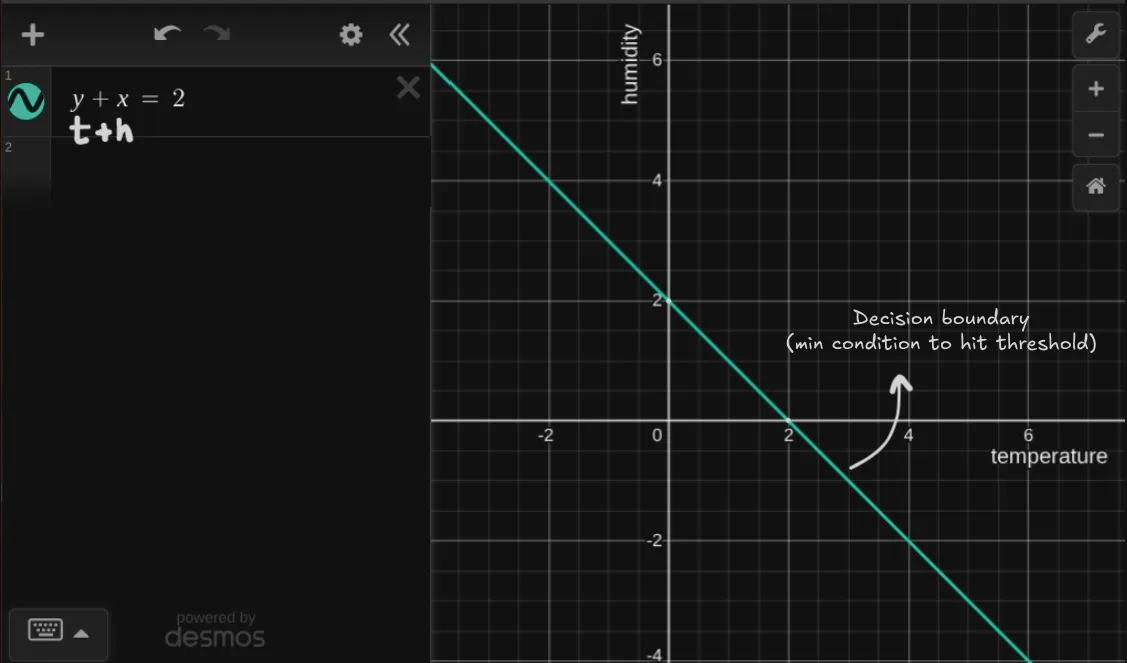
Say, weights are 1 for temperature () and 1 for humidity (), and the threshold () is .
What’s the minimum condition for the neuron to output 1?
This is the equation of a line! say as axis and as axis, this is what the graph looks like:
Explanation
What does this line signify?
It’s the decision boundary or simply put the minimum requirement for neuron to fire/activate. So as per the graph any point on the line i.e will be classified as 1 (go outside) and any point below the line i.e will be classified as 0 (stay in).
but wait we have an inequality to handle:
here is the graph of the inequality:
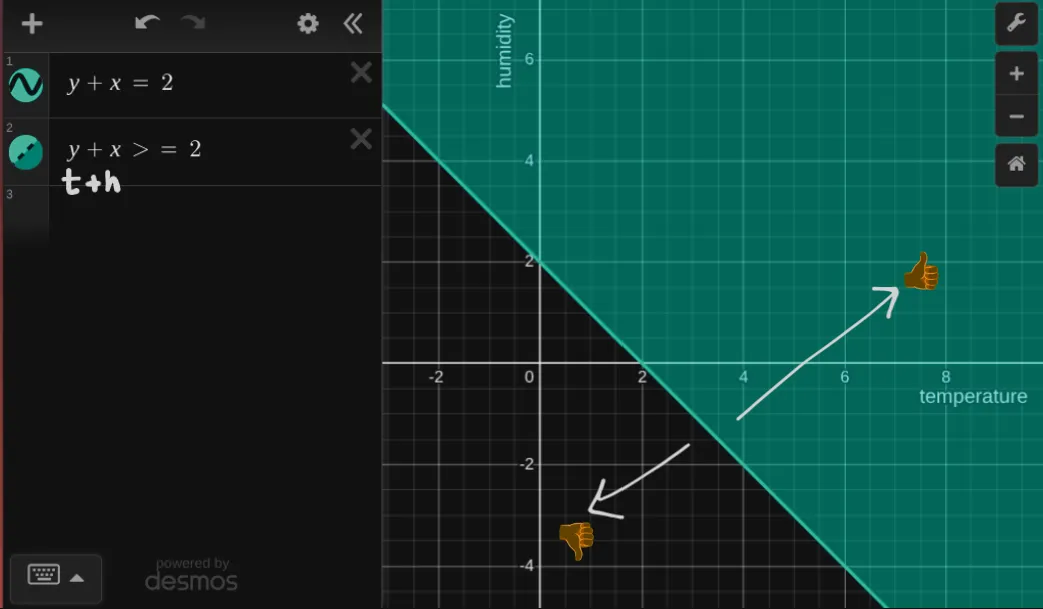
Explanation
Its whole fucking area now. This means any value of that falls in this area will be classified as 1 (go outside) and value of that falls outside this area will be classified as 0 (stay in).
Now the weights (importance) of the inputs influences whether to go out or not.
say weight of is and weight of is . This means we don’t care about temperature and only care about humidity, so the line will be parallel to axis and will pass through
Here is a visual of how weights influence the line:
Alright maybe I played too much there 💀 but you get the point. Go ahead play around with the weights and see how it changes the line: MCP Neuron plot
Limitations
Even though the MCP neuron was a breakthrough, it comes with some important limitations:
- No learning or adaptation: The weights and threshold (unlike biological neurons) are fixed and must be set manually, so the neuron can’t adjust or improve itself based on experience or new data.
- Works only with simple, linearly separable problems: It can only handle binary signals and can solve logic gates like AND, OR, and NOT, but fails for more complex cases like XOR that can’t be separated by a straight line.
This made Frank Rosenblatt think: “How about making the MCP neuron learn?”
Perceptron
The basic structure is just like the MCP neuron, but here’s the big difference: the weights and threshold can be adjusted through learning!
How do biological neurons learn?
Neurons that fire together, wire together.
Neurons talk to each other through connections called synapses. When two neurons send signals (or “fire”) at the same time a lot, their connection gets stronger. When they don’t fire together often, their connection gets weaker.
Definition (Hebbian principle)
This strengthening and weakening is how your brain learns. This is called Hebbian principle.
Explanation
An analogy would be the more you hang out with a friend, the stronger the connection between you two.
When you practice a song on the piano, the neurons involved fire together a lot, and their connections get stronger. That’s why you get better with practice!
If you stop using a skill or forget something, those neuron connections weaken because they’re not being used.
While the main idea is about making connections stronger or weaker, a lot more complex stuff happens in the brain:
- Add more “receivers” (receptors) at a synapse to catch signals better.
- Change how many chemical messengers (neurotransmitters) are sent between neurons.
- Even grow new synapses or get rid of old ones
Deriving Perceptron from MCP Neuron (mathematically)
It’ll get a bit mathy here, but I promise it’ll be worth it. So we want our neuron to fulfill following conditions:
- Adjust threshold based on learning (unlike MCP neuron, where threshold and weights are fixed)
- Adjust weights based on learning
Let’s break this down step by step.
Step 1: Starting with the MCP Neuron
Proof (The Basic MCP Model)
First, let’s recall how the MCP neuron works. It has two main components:
- Weighted Sum:
- Activation Function:
This model works, but the threshold is fixed. We need to make it learnable.
Step 2: Making the Threshold Learnable
Proof (Transforming the Threshold)
Let’s transform the fixed threshold into something we can learn:
- First, write out the activation condition:
- Rearrange by subtracting from both sides:
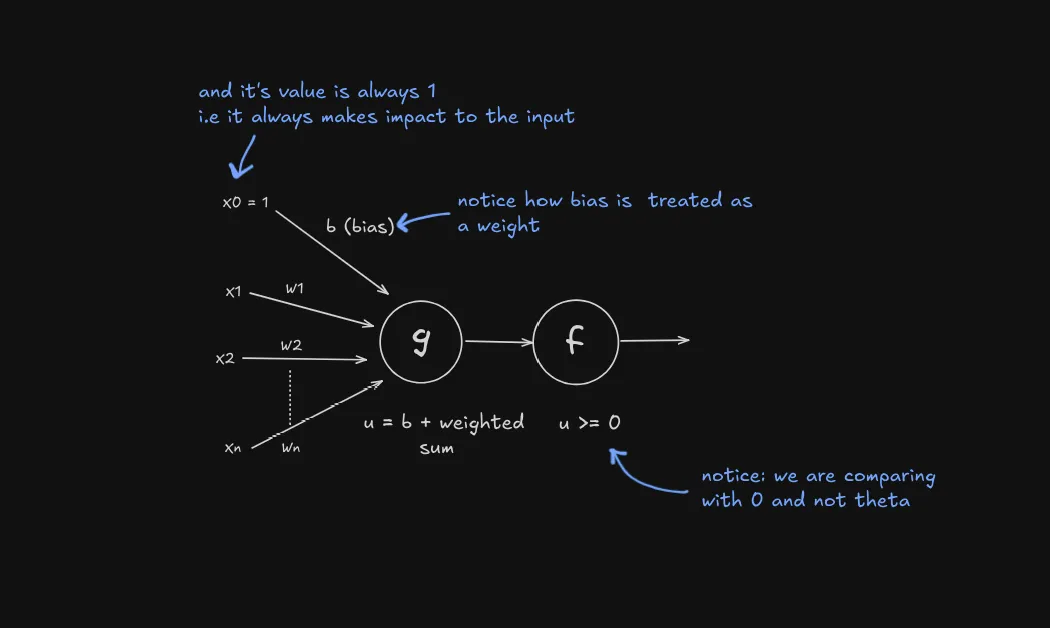
- Here’s the key insight: Let’s define and call it the bias:
This can also be written as:
where is a constant input representing the bias. So we are treating it a combination of weight and input.
Now instead of a fixed threshold , we have a bias term as weight that can can be updated based on learning. This is how the perceptron model looks like so far:
Step 3: Learning Rule
By learning we mean, learning by trial and error:
- The perceptron makes a prediction based on its current weights
- It compares its prediction with the correct answer
- If there’s an error, it adjusts its weights slightly in the direction that would reduce the error
- This process repeats with many examples until the perceptron achieves good accuracy
Example:
- For 5+5 if perceptron predicts 9 and correct answer is 10, it will calculate the error and adjust weights to improve next time until it gets the answer right.
This iterative process of prediction → error calculation → weight adjustment is what we mean by “learning” and this is what training a perceptron means. It gradually discovers the optimal weights through experience, rather than having them pre-programmed.
Definition (The Learning Algorithm)
Now that even bias is a weight, we only need to adjust the weights based on learning.
We’ll use the perceptron learning rule:
Explanation (What does this mean?)
In simple terms:
- is the weight of the th input
- is the learning rate
- is the predicted output
- is the correct output
- is the th input
What’s Learning Rate ()?
Think of it like a tap that controls how fast we adjust the weights:
- If learning rate is too high (tap fully open): We make big adjustments and might overshoot the correct weights, like flooding a sink or destroying a settlement if it’s a dam 💀
- If learning rate is too low (tap barely open): Learning happens very slowly, like filling a swimming pool drop by drop
- Just right (tap opened moderately): We learn steadily without overshooting
For most simple perceptron tasks, a learning rate between 0.1 and 0.01 works well. This gives us enough movement to learn while maintaining stability.
| Learning Rate | Description | Training Behavior |
|---|---|---|
| 1.0 | High | Quick learning but might overshoot |
| 0.1 | Moderate | Good balance of speed and stability |
| 0.01 | Low | Stable but slow learning |
Why multiply by input ()?
This ensures we only adjust weights that actually contributed to the mistake:
Imagine you’re building a dam and notice water leaking. You only want to reinforce the parts where water is actually flowing (input = 1), not the dry parts (input = 0).
- If input was 0: That input didn’t contribute to the mistake, so (no adjustment)
- If input was 1: That input did contribute, so we adjust its weight based on how wrong we were
I don’t know why I’m obsessed with dams, but it’s a good way to think about it.
Note
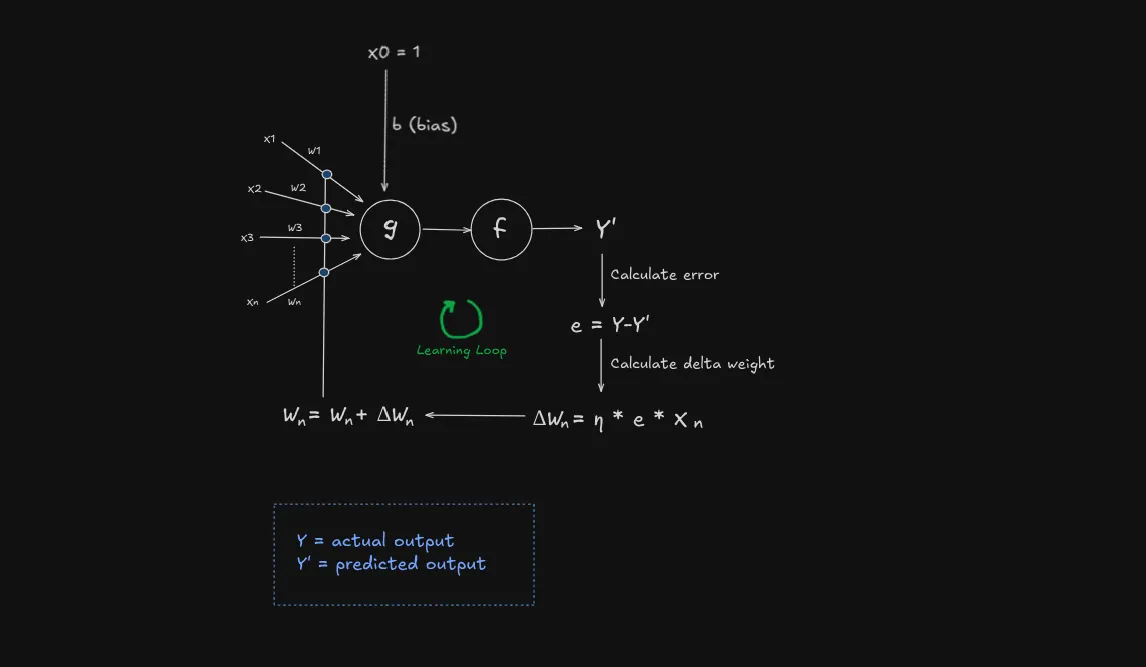
If you notice, since bias has a constant input of , it’s weight () is updated every time since it’s input is always contributing to the output.
Let’s see what the perceptron model looks like:
Iterations, Epochs, and Convergence
Training a perceptron is a bit like practicing a new skill: you rarely get everything perfect on your first try. When training, the perceptron goes through the entire dataset, making predictions and adjusting its weights whenever it makes a mistake.
Definition (Iteration)
This process of looking at one example and possibly updating the weights is called an iteration.
Example: It’s like going through one math problem with the student
Definition (Epoch)
When the perceptron has seen every example in the training set once, that’s called an epoch.
Example:
- 1 epoch is like completing an entire homework sheet (consists of multiple problems)
- Multiple epochs are like completing same homework sheet multiple times.
But why do we need multiple epoch / passes through the data?
Remember learning rate? Well usually a small learning rate is used for a stable learning. This means that the perceptron will make small changes to its weights each time it makes a mistake at each example.
By going through the data multiple times, the perceptron can slowly and steadily improve, fixing mistakes it couldn’t fix in just one round.
Definition (Convergence)
Convergence happens when the perceptron can go through the entire training set during an epoch without making any mistakes given that the data is linearly separable. At this point, it has found a set of weights that correctly classifies all the training data.
Example: If the student can solve all the problems in the homework sheet correctly without help, we say the perceptron has converged.
Proving this is a bit out of scope of this post, but you can read more about it in this medium post.
So we keep doing homework sheets (epochs) until the student(perceptron) masters the material (convergence)!
Why do we use epochs if model will converge at some point?
You might think:
Problem
why we use epochs if the model will eventually converge, couldn’t we just run it until it reaches that point?
While this idea makes sense in theory, there are several practical reasons why we rely on epochs.
-
Computational Efficiency: Running the model until convergence would be very slow, especially for large datasets. If convergence is slow or if noise in the data prevents the loss from fully stabilizing. By setting a number of epochs, we impose a manageable boundary on resource use. Also allow us to stop early if the model is performing well.
-
Preventing Over-fitting: If a model runs for too long, it risks over-fitting, where it learns not just the general patterns in the training data but also its noise and quirks. This reduces its ability to perform well on new, unseen data. Limiting the number of epochs helps stop training before over-fitting becomes a problem.
-
Monitoring and Validation: Epochs give us regular checkpoints to assess the model’s performance. After each epoch, we can evaluate the model on a separate validation set. This allows us to stop early, halting training if the validation loss starts to rise (a sign of over-fitting).
The number of epochs is a tunable. By experimenting with different values, we can determine the optimal number of passes through the data that maximizes performance on a validation set.
Linear Separability
Just like the MCP neuron, the perceptron can only solve problems that are linearly separable.
How Is It Different from the MCP Neuron?
The perceptron has a superpower: it can learn its weights and threshold() through training. The MCP neuron, on the other hand, has fixed weights and a threshold set by hand, like a bouncer with a strict guest list that never changes.
Visualizing the Decision Boundary
Taking the same example of temperature () and humidity (). The perceptron computes a weighted sum plus a bias.
Example (Perceptron equation)
Starting with the perceptron equation:
we can simplify it for our example:
setting and and we get:
The decision is made when:
the decision boundary is:
Plotting this on the graph we get:
We have a extra term which allows us to shift the line in 2D space unlike the MCP neuron where we had a fixed threshold. During the training process is learned until the model converges.
Adding up the inequality we get:
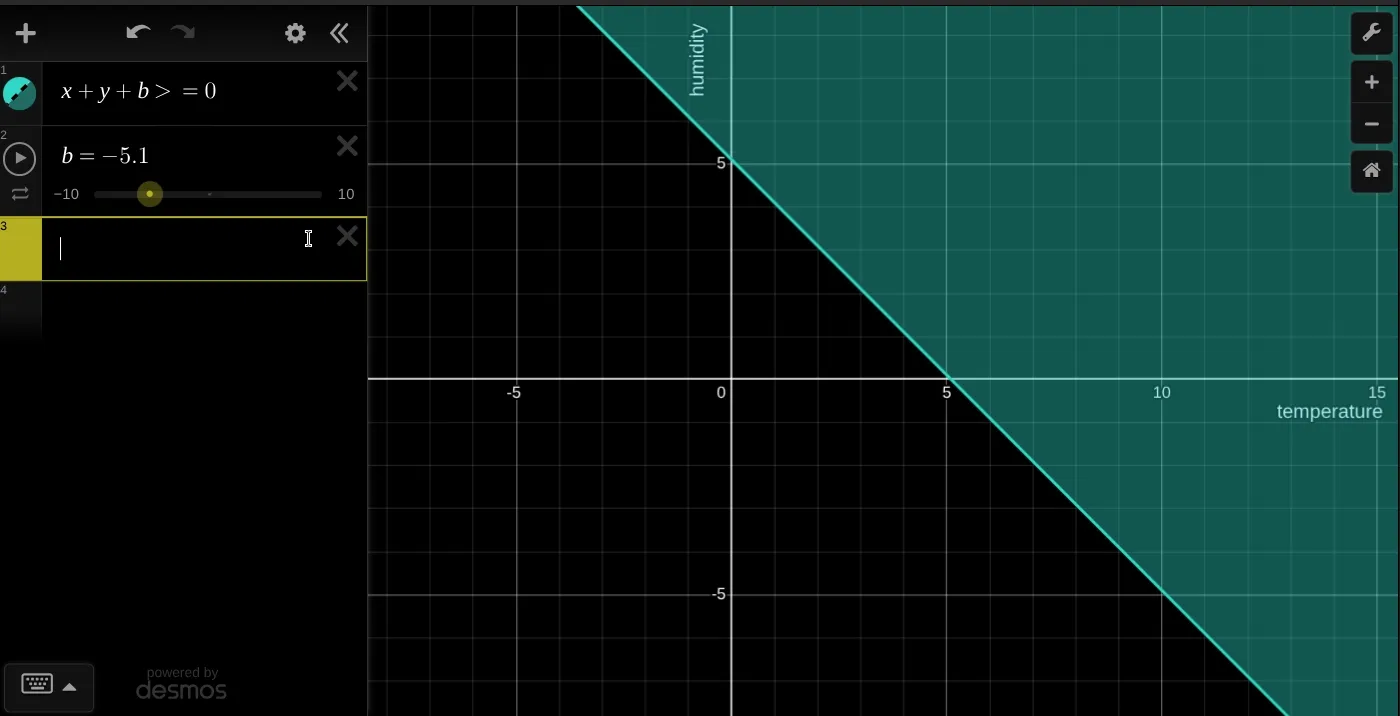
Go ahead and play with the weights and bias to see how it changes the line: Perceptron plot
Implementing Perceptron
Now, let’s implement a perceptron in Python.
Example (Perceptron class)
import numpy as np
class Perceptron:
def __init__(self, learning_rate=0.1, epochs=100):
self.weights = None
self.bias = None
self.learning_rate = learning_rate
self.epochs = epochs
def activate(self, x):
# Step function: output 1 if sum >= 0, else 0
return 1 if x >= 0 else 0
def weighted_sum(self, x):
return np.dot(self.weights, x) + self.bias
def predict(self, x):
# Weighted sum of inputs + bias
return self.activate(self.weighted_sum(x)) So far it’s same as the MCP neuron with addition of bias and in activation function we are comparing the weighted sum with 0 instead of threshold.
Now we implement the training algorithm, from our understanding so far we need:
- Initialize weights and bias with some random values (preferably small)
- We need to iterate over the whole training data epochs times
- Now in each epoch we need to go through each example and check if the prediction is correct
- If prediction is incorrect, we update the weights and bias using the perceptron learning rule
- We also need to keep track of the number of errors in each epoch and stop if it’s 0
Example (Training algorithm)
import numpy as np
class Perceptron:
...
def train(self, x, y):
training_data_length = x.shape[1]
self.weights = np.random.randn(training_data_length) * 0.01
self.bias = np.random.randn() * 0.01
for epoch in range(self.epochs):
total_error = 0
for i in range(len(x)):
prediction = self.predict(x[i])
error = y[i] - prediction
if error != 0:
self.weights += self.learning_rate * error * x[i]
self.bias += self.learning_rate * error #notice
total_error += abs(error)
# Stop early if no errors in this epoch
if total_error == 0:
print(f"Converged after {epoch+1} epochs")
breakLearning AND gate
Let’s make the perceptron learn the AND gate. The AND gate takes two binary inputs and outputs 1 only if both inputs are 1. Here’s how we can set up the training data and test the perceptron.
Example (Training Perceptron for AND gate)
import numpy as np
# Define training data for AND gate
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # Input pairs
y = np.array([0, 0, 0, 1]) # Expected outputs
# Initialize and train the perceptron
perceptron = Perceptron(learning_rate=0.1, epochs=100)
perceptron.train(X, y)
# Test the perceptron
print("Testing AND gate:")
for i in range(len(X)):
prediction = perceptron.predict(X[i])
print(f"Input: {X[i]}, Predicted: {prediction}, Expected: {y[i]}")
I hope this doesn’t require much explanation, pretty straightforward.
Answer (Output)
Converged after 8 epochs
Testing AND gate:
Input: [0 0], Predicted: 0, Expected: 0
Input: [0 1], Predicted: 0, Expected: 0
Input: [1 0], Predicted: 0, Expected: 0
Input: [1 1], Predicted: 1, Expected: 1
Activity
Exercise (Testing perceptron)
Try exploring the perceptron’s capabilities further:
- AND/OR/NOT gates
- XOR Gate: Does it work? Why or why not?
- Simple Addition Task: Can the perceptron learn this?
Hints:
- For the XOR gate, you may notice the perceptron struggles. This is because XOR is not linearly separable, meaning a single perceptron cannot solve it.
- For the addition task, the perceptron may not learn the sum perfectly since it outputs binary values (0 or 1) and struggles with multi-valued outputs.
Limitations
The perceptron is a powerful yet simple model, but it has key limitations:
- Linear Separability: The perceptron can only solve problems where the data can be separated by a single straight line (in 2D) or a hyperplane (in higher dimensions). For example:
- It can learn AND and OR gates, which are linearly separable.
- It cannot learn the XOR gate, as the classes (0 and 1) cannot be separated by a single line.
- Binary Output: The perceptron outputs only 0 or 1 due to the step activation function, making it unsuitable for tasks requiring continuous or multi-valued outputs (e.g., predicting exact sums in the addition task).
Example (XOR Issue):
# Trying XOR gate
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0]) # XOR outputs
perceptron = Perceptron(learning_rate=0.1, epochs=100)
perceptron.train(X, y)
# Test XOR
print("Testing XOR gate:")
for i in range(len(X)):
prediction = perceptron.predict(X[i])
print(f"Input: {X[i]}, Predicted: {prediction}, Expected: {y[i]}")Running this will likely show incorrect predictions because XOR requires a non-linear decision boundary, which a single perceptron cannot achieve.
What’s Next? To address these limitations, we can explore:
- Multi-layer Perceptrons (MLPs): Combining multiple perceptrons in layers allows learning non-linear patterns like XOR.
- Different Activation Functions: Using functions like sigmoid or ReLU enables continuous outputs.
- Advanced Models: Neural networks or other algorithms can handle more complex tasks.
Try the exercises above and experiment with the perceptron to see these limitations in action!
Conclusion
This was a long ass post so I conclude this here. I hope you enjoyed reading this as much as I enjoyed writing it. If you find any mistakes, please let me know.
Thanks for reading :)
Also here is an interesting problem to chew on: